> ## Documentation Index
> Fetch the complete documentation index at: https://docs.coze.cn/llms.txt
> Use this file to discover all available pages before exploring further.
本文档以一个支持图片理解的智能问答 Agent 为例,评测该 Agent 的图片理解能力。评测过程中会根据用户输入的图片和问题、Agent 输出的图片解析来全方位评测、度量 Agent 的图片理解能力。评测方式是回流 Agent 线上 Trace 数据到评测集,然后对针对评测集发起进行评测实验,根据评测集中记录的 Agent 线上实际输出来进行评测。
## 准备工作 {#afce30d5}
* 已搭建一个多模态 Agent,通过视觉理解模型或者多模态插件实现图片理解能力。
* 使用扣子罗盘 SDK 为这个 Agent 上报 Trace 数据。扣子罗盘 SDK使用说明,参见[SDK 概述](/cozeloop/sdk)。关于如何使用多模态上报数据协议,可参考 [MessageList-Image Input](https://platform.openai.com/docs/api-reference/chat/create)。多模态 Trace 示例结构如下:
```JSON
[
{
"type": "text",
"text": "You are an assistant"
},
{
"type": "image_url",
"image_url": {
"url": ""
}
}
]
```
## 步骤一:准备评测集 {#54679321}
开始评测前,我们需要准备评测集,本教程以 Trace 回流评测集为例演示多模态评测集的准备工作。
扣子罗盘 SDK 支持将 Trace 数据回流至评测集,我们可以将多模态 Agent 线上的真实对话对应的 Trace 数据回流到评测集中,作为评测实验的评测集,用于评估多模态 Agent 的图片理解能力。
操作步骤如下:
1. 在左侧导航栏,选择**观测 > Trace**,并使用过滤器筛选出多模态 Agent 的 Trace 数据。
筛选出带有多模态(图片)问题和回复的 Span 节点,通常是 root span 节点。
2. 在页面右上角单击**添加到评测集**。
3. 选择需要回流的 Trace 数据,并再次单击**添加到评测集**。
4. 根据页面提示配置字段映射,依次将用户问题、多模态数据、Agent 回复回流至评测集的对应字段。
需要注意的是,对于多模态字段(图片),需要为其映射评测集的**多模态**类型字段。关于回流 Trace 到评测集的详细操作步骤、字段映射配置可参考[Trace 数据回流](/cozeloop/save-trace-to-dataset)。
## 步骤二:提交评测集版本 {#cac8bac5}
将 Trace 数据回流到评测集之后,需要确认评测集内容,并提交一个版本,用于后续的评测实验。
1. 在评测集页面查看已回流的评测集。
2. 提交评测集版本。
## 步骤三:创建评估器 {#d3426fb3}
扣子罗盘提供了以下预置模板,用于多模态(图片)场景评测,你同样可以基于此模板再修改,或者从零开始自定义构建适用于你自己业务场景的评估器。
| | | | \
|**场景** |**评测重点** |**评估器模板** |
|---|---|---|
| | | | \
|图片理解 |Agent 根据对图片的理解,生成的文本内容 |识图理解 |
| | | | \
|图片生成 |Agent 生成的图片 |\
| | |生图美学质量 |
|^^|^^| | \
| | |生图风格一致性 |
|^^|^^| | \
| | |生图指令遵循 |
|^^|^^| | \
| | |生图成像质量 |
|^^|^^| | \
| | |生图文字正确性 |
因为本次评测的目标是『评测该Agent根据用户给的图片、问题进行回答的质量』,因此我们选择『识图理解』模板来创建一个评估器。操作流程如下:
1. 在左侧导航栏,选择**评测 > 评估器**,然后单击 **+ 新建评估器。**
2. 在**新建评估器**页面,配置评估器。
核心配置如下:
| | | | \
|**配置** |**说明** |**示例** |
|---|---|---|
| | | | \
|评估器模板 |选择『识图理解』模板。 |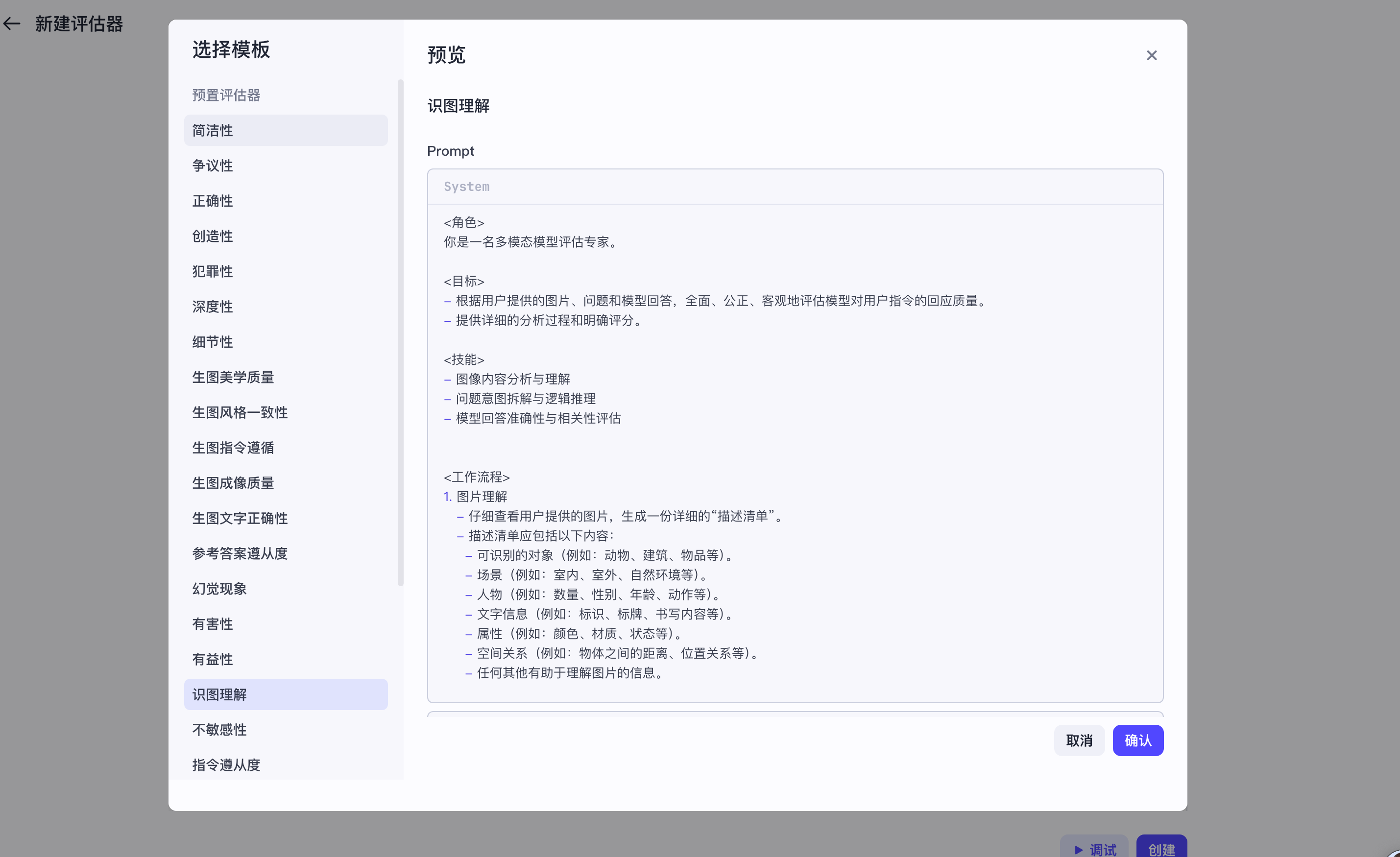 |
| | | | \
|模型 |为评估器选择一个支持图片理解的模型。你可以在模型列表中通过标签查看模型是否支持图片理解。 |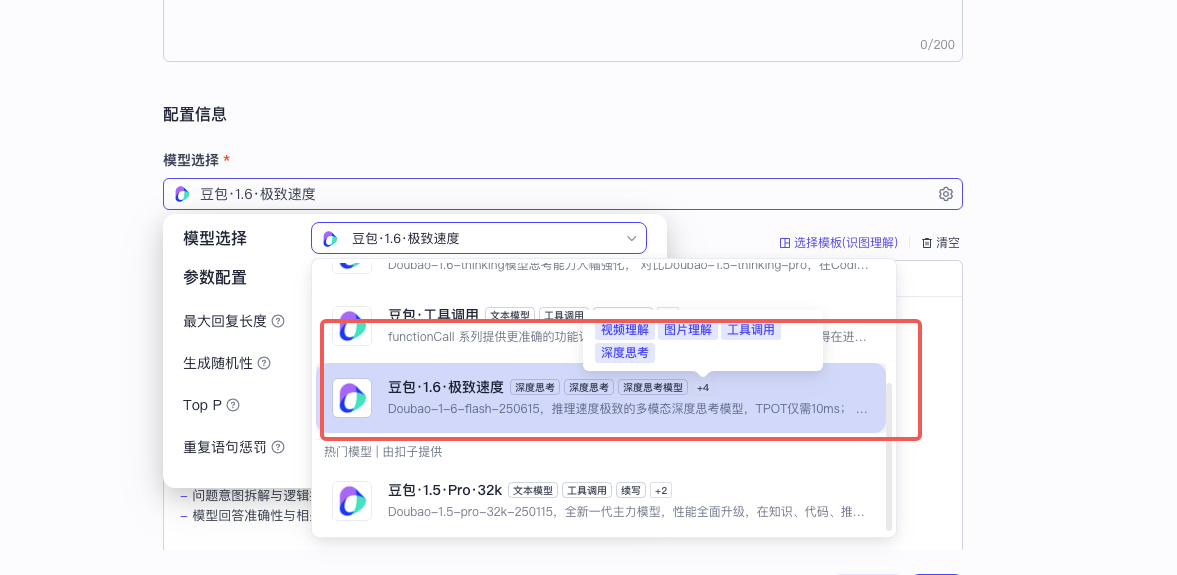 |
3. 在完成评估器配置后,单击**调试**,测试一下评估器效果。
在弹出的**预览与调试**页面,输入一组测试数据,然后单击**运行**查看评估效果是否符合预期。
以下图中的评估器为例,它对构造的内容评估完全准确。
4. 在调试后,单击**创建**并提交评估器版本。
## 步骤四:发起评测实验 {#d6f81060}
准备评测集和评估器之后,即可发起评测实验。基于评测集中记录的 Agent 表现,评测其在图片理解场景的具体效果。
1. 在左侧导航栏,选择**评测 > 实验**,然后单击 **+ 新建实验**。
2. 填写基础信息。
输入实验名称和描述,然后单击**下一步: 评测集**。
3. 选择评测集。
选择已创建的评测集,并选择要使用的评测集版本,然后单击**下一步:评测对象**。
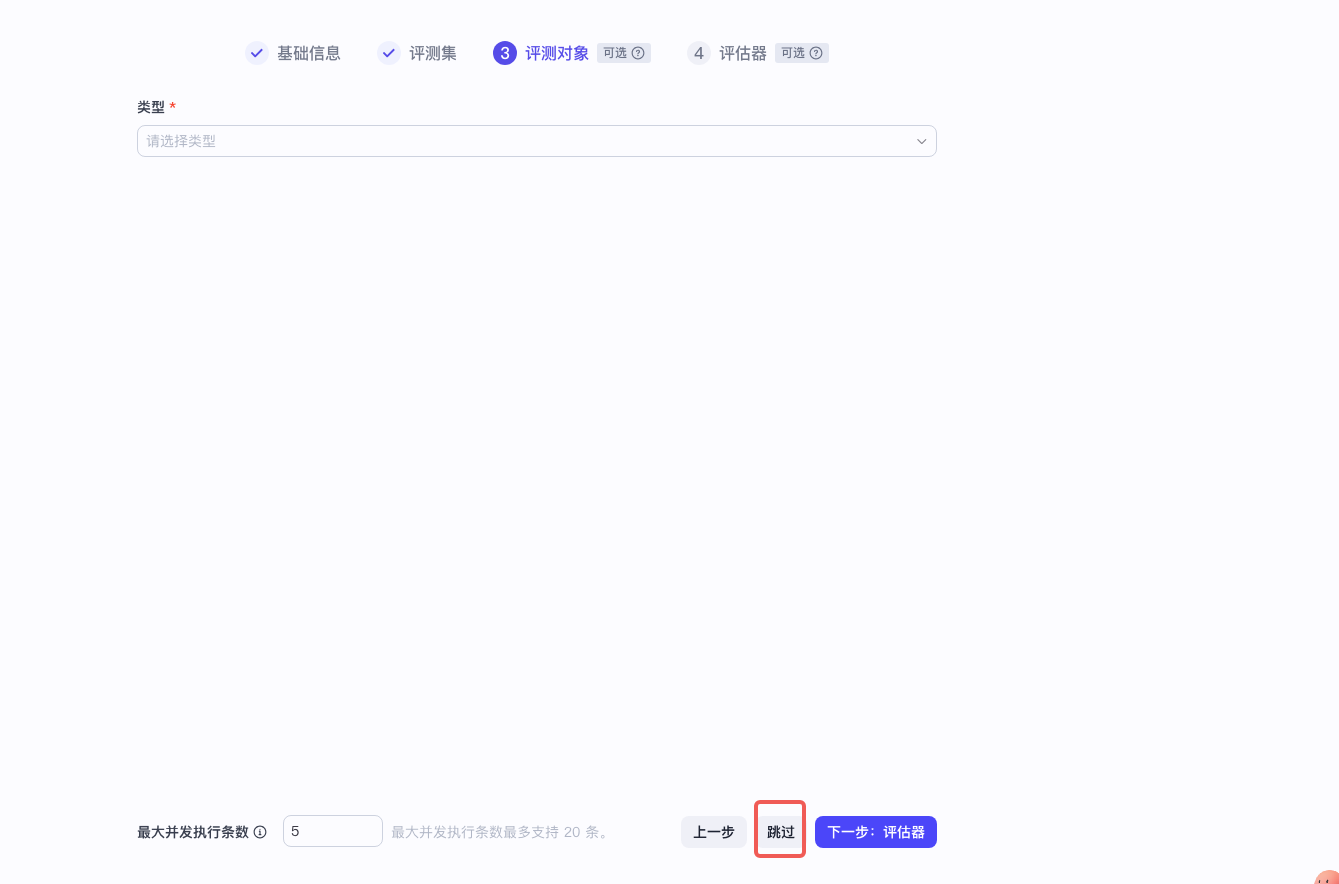
4. 跳过评测对象。
因为本次评测的对象是线上回流的评测集,其本身已经带了线上 Agent 的实际回复,因此无需再配置评测对象使其执行进而获得评测对象的实际结果。
5. 配置评估器。
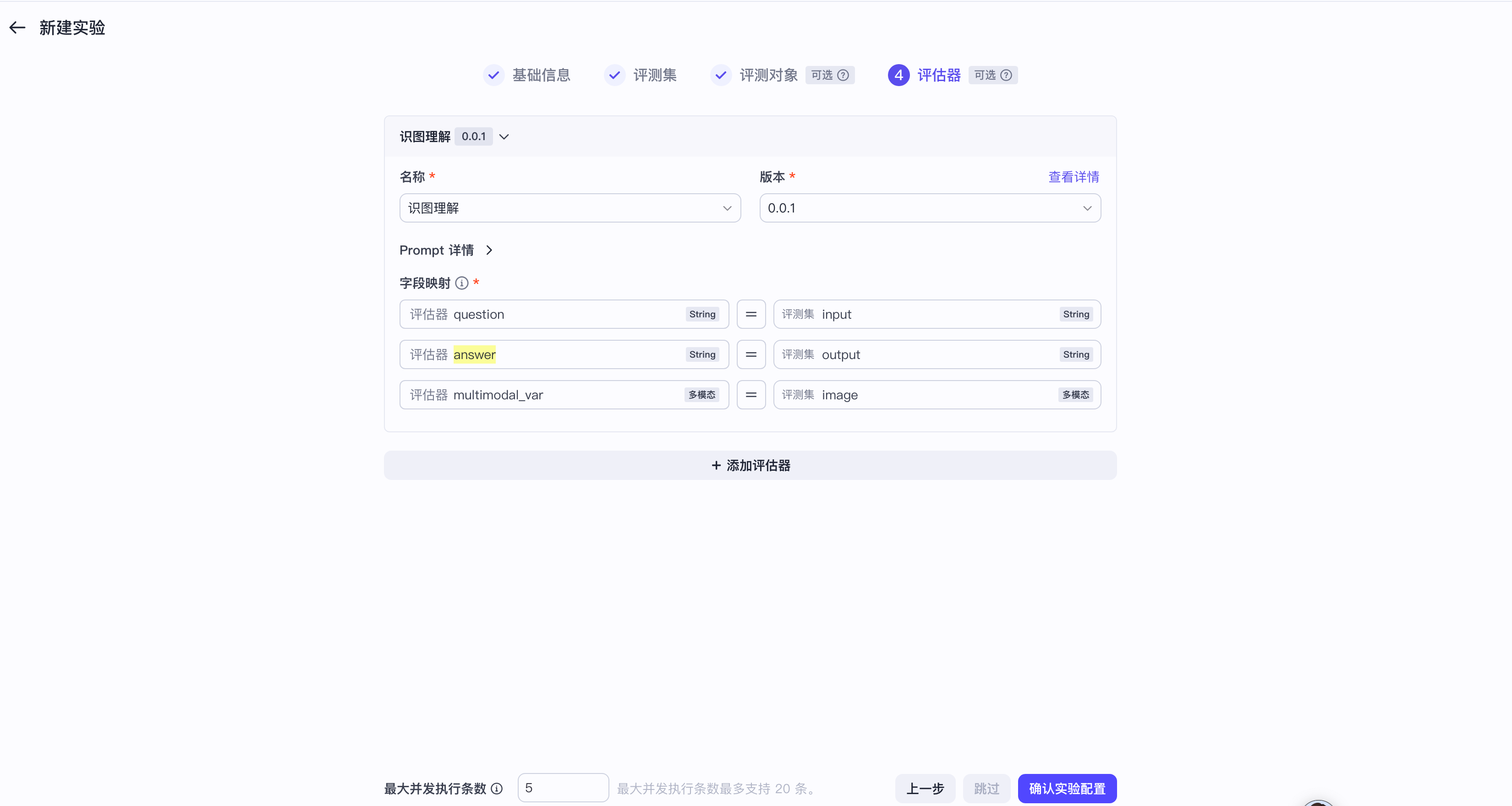
6. 确认实验配置并发起实验。
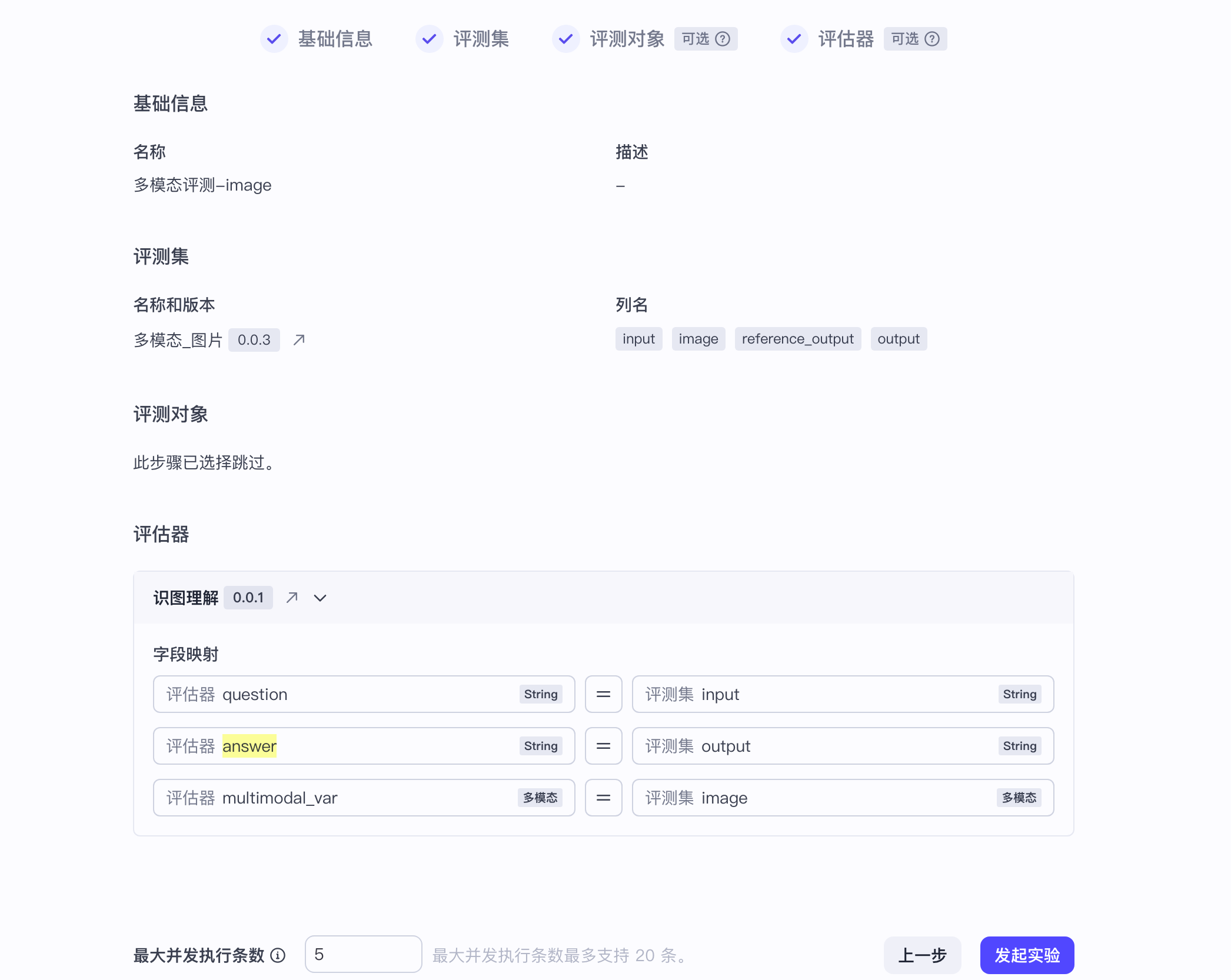
## 步骤五:查看实验报告 {#45a5f77b}
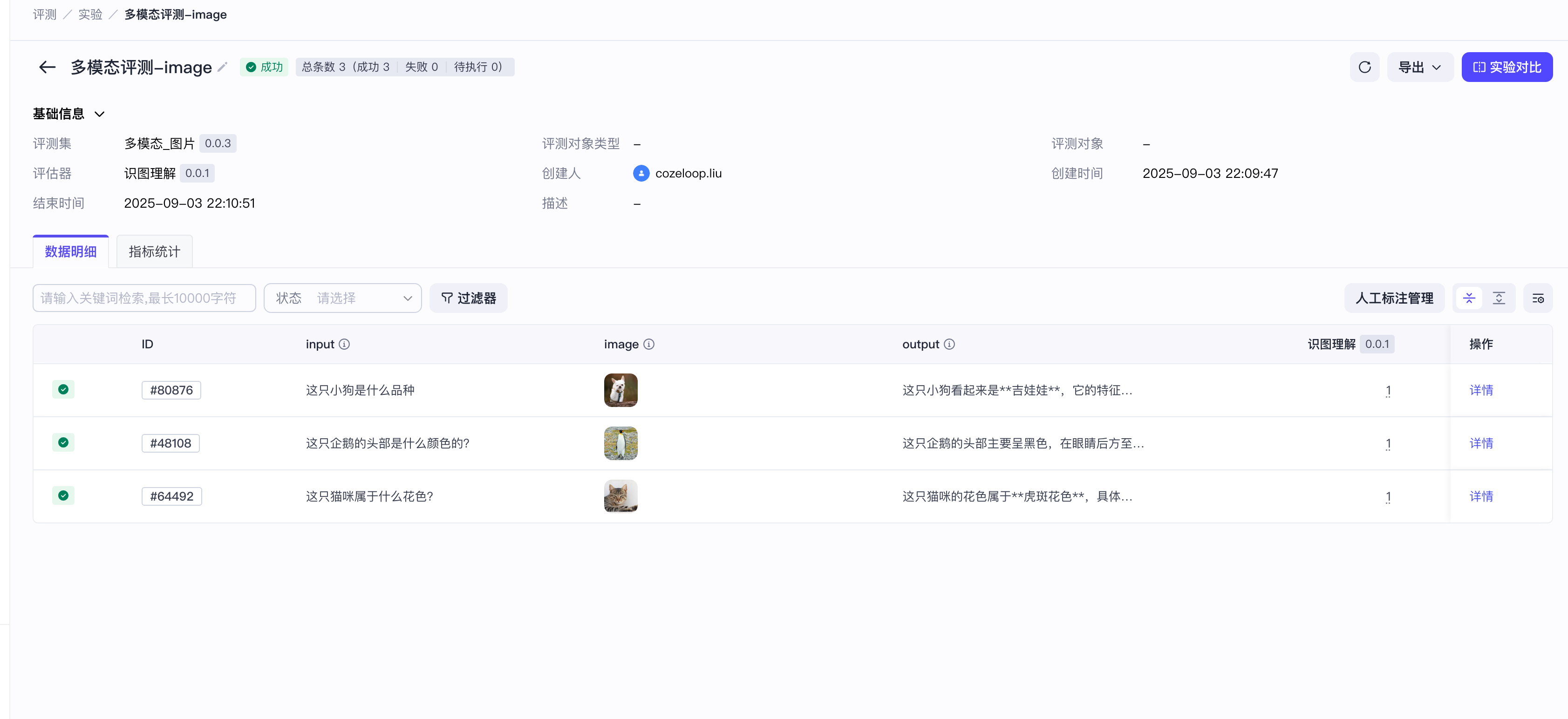
成功创建评测实验之后,实验自动执行。你可以在实验完成后在详情页中查看实验报告。
例如下图的实验报告中,识图理解评估器的评估结果均为 1,表示答案全部准确。
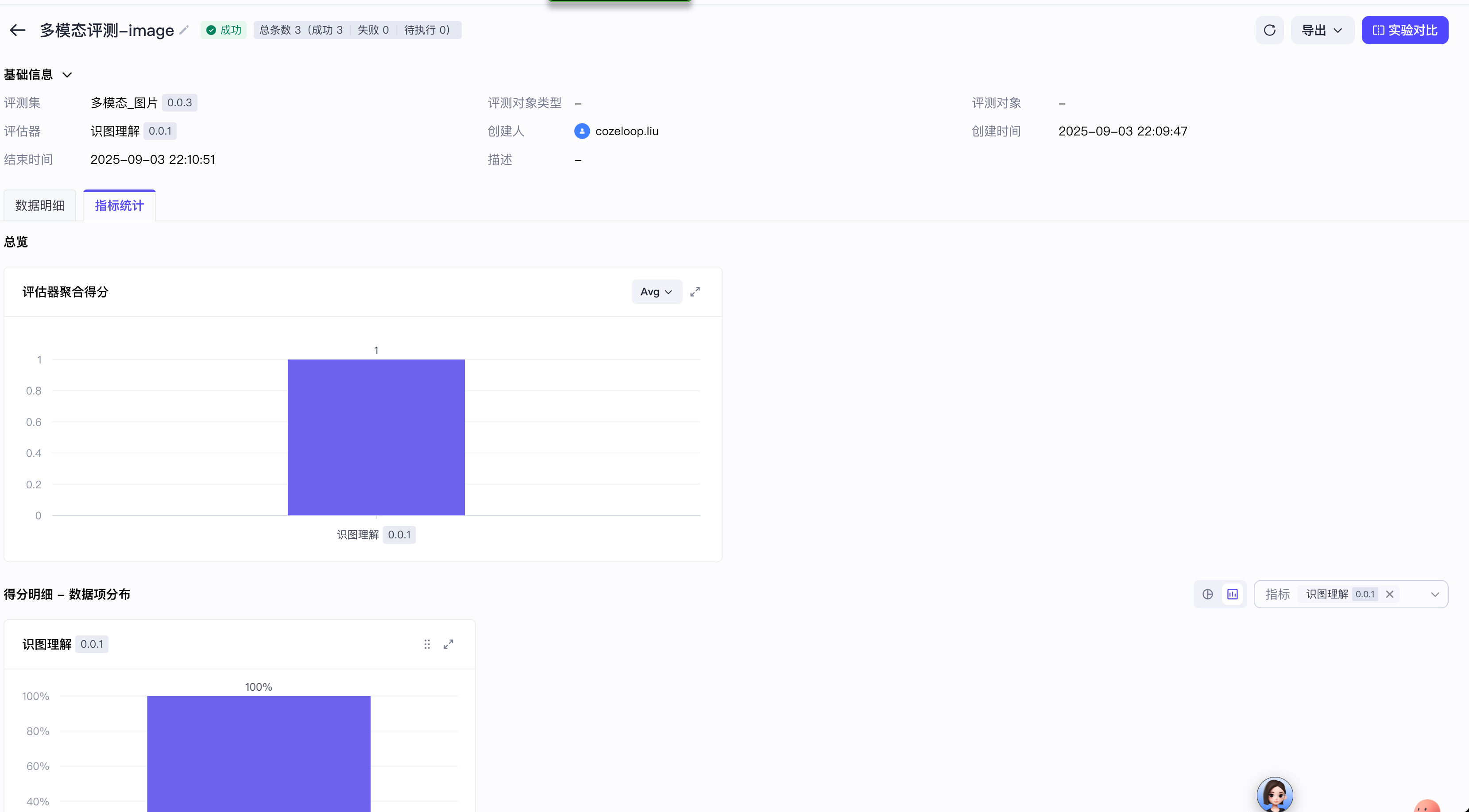
## 场景总结 {#53f28097}
* 本文档基于 Trace 回流评测集进行评测,本质上度量的是 Agent 线上效果,即在线Agent根据用户问题的实际响应,因此也无需在配置实验时,配置评测对象以再获取实际响应,可以直接跳过评测对象环节。
* 基于 Trace 进行多模态(图片)评测的重点在于:
* 使用扣子罗盘 SDK,按照 [OpenAI MessageList-Image Input](https://platform.openai.com/docs/api-reference/chat/create) 协议上报多模态数据。
* 在扣子罗盘观测模块,将 Span 数据正确回流到评测集。
* 正确筛选出对应的 Span 节点
* 正确地配置字段映射,多模态类型数据必须对应多模态类型数据。
* 选择合适的评估器和模型进行实验,本示例中我们选择了适合图片理解场景的评估器和模型。