AI 助手
扣子 AI 帮助与支持
你好,我是 扣子 文档问答助手 🎉
你在阅读当前文档的过程中,无论对文档概念的解释,还是文档内容方面的疑问,都可以随时向我提问,我会全力为你解答
推荐问题
如何快速了解这个空间的核心内容?
有哪些近期更新的重点文档?
我应该从哪些文档开始阅读?
文档反馈
在评测过程中,评估器充当裁判的角色,通过量化评测对象的输出结果来评估其表现。在发起评测实验前,至少要创建一个评估器。本文指导你在扣子罗盘中创建和管理评估器。
评估器概述
评估器(Evaluator)是用于自动化或半自动化评估工具。评估器通过预定义的规则,对评估对象的输出进行多维度分析,生成可量化的指标和归因结论。
在执行评测实验时,LLM 评估器会根据 Prompt 中预设的标准和规则对评估对象的输出进行打分,并提供得分原因。得分范围从 0.0 到 1.0,1.0 表示完全满足评分标准,0.0 表示完全不满足评分标准。开发者也可以在评估器中自行定义评估标准和分值范围。
说明
LLM 评估器的得分和原因由 AI 生成,可能存在偏差。扣子罗盘支持对评估器的得分进行人工校准和修改。详细说明可参考人工标注评测数据。
评估器类型
预置评估器与自建评估器
评估器用于根据预设的标准和规则判断预期输出和实际输出的差异,开发者可以根据评测实验的业务场景,自行创建评估器、编写评估器 Prompt。
根据来源划分,评估器可分为预置评估器与自建评估器。
- 预置评估器:由扣子罗盘统一提供,覆盖了各种评估实验的典型场景,例如 Agent 任务完成度、轨迹质量等。开发者可以在评测实验中直接使用这些预置评估器。关于预置评估器的详细说明,可参考预置评估器。
- 自建评估器:开发者根据自身业务需求创建的。 扣子罗盘提供一系列评估器模板,开发者也以基于这些模板二次开发,打造符合自己业务场景的自建评估器。
LLM 评估器和 Code 评估器
根据评估器的评估方式,我们可以将评估器分为以下两种:
- LLM 评估器:大模型评估器,通过大模型判断预期输出和实际输出的差异,用于模型自动化评测的场景。评测的标准和评分由大模型的 Prompt 来定义。
- Code 评估器:代码评估器,通过执行代码函数来对比预期输出和实际输出,检查输出是否包含特定的文本或是否符合特定的格式要求。适用于对评测的精确性要求比较高的场景,例如 JSON 格式判断等。目前支持 Python 和 JavaScript 两种开发语言的 Code 评估器。
创建 LLM 评估器
参考以下步骤,创建一个 LLM 评估器。
-
访问扣子罗盘,并在左侧导航栏顶部,选择一个空间。
-
在左侧导航栏,选择评测 > 评估器。
-
在页面右上角单击 + 新建评估器,并选择 LLM 评估器。
-
选择一个评估器模板,或者单击使用自定义创建。
扣子罗盘预置了适合多种评测场景的评估器模板供你快速创建评估器,这些模板分别从各种角度评估评测对象的输出是否符合指定的要求,例如评估输出的间接性、争议性等。你可以根据评估器类型(LLM 或 Code)、评估对象、评估目标和业务场景,筛选不同的评估器模板。
如果评估器模板不符合你的需求,你也可以单击自定义创建LLM评估器,自己编辑评估器的提示词。
-
在新建评估器页面,参考以下信息配置评估器。
配置
说明
名称
输入评估器名称。
描述
提供一个评估器的说明信息。
模型选择
使用豆包模型。
目前,评估器仅支持豆包模型。Prompt
输入评估器的提示词,指示评估器如何进行评估,也可以使用内置的 Prompt 模板或基于模版进行修改。
单击选择模板链接,查看并选择一个Prompt 模板。
+ 添加 User Prompt(可选)
当评估规则较为复杂时,可以通过单击 + 添加 User Prompt 添加 User Prompt,以强调特定的评估规则。User Prompt 的优先级高于 System Prompt,因此模型会优先处理和评估 User Prompt 中输入的规则内容。这样可以确保复杂规则得到准确的关注和应用。
User Prompt 支持设置多模态变量。你可以在输入框右上角单击图片标识,并输入多模态变量名称。后续创建评估实验时,注意应为此变量映射多模态类型的字段。
-
在完成评估器配置后,单击调试,测试一下评估器效果。
在弹出的预览与调试页面,输入一组测试数据,然后单击运行查看评估效果是否符合预期。
以下图中的评估器为例,它对构造的output内容评估完全准确。
-
在调试后,单击创建并提交评估器版本。
创建 Code 评估器
说明
Code 评估器默认支持 Python 和 JavaScript 官方库,也支持以下第三方库:
- JavaScript:
- lodash-es: “4.17.10”
- Python:
- numpy (v2.2.2): “numpy”
- pandas (v1.5.2): “pandas”
- jsonschema (v4.21.1): “jsonschema”
- scipy (v1.14.1): “scipy”
- sklearn (v1.26.4): “scikit-learn”
参考以下步骤,创建一个 Code 评估器。
- 访问扣子罗盘,并在左侧导航栏顶部,选择一个空间。
- 在左侧导航栏,选择评测 > 评估器。
- 在页面右上角单击 + 新建评估器,并选择 Code 评估器。
- 选择一个评估器模板,或者单击使用自定义创建。
扣子罗盘预置了 Python 和 JavaScript 两种语言、适合多种评测场景的 Code 评估器模板,支持从各种角度评估评测对象的输出是否符合指定的要求,例如文本包含判断、文本等值判断等。如果预置的评估器模板不符合你的需求,你也可以单击自定义创建Code评估器,自己编写 Code 评估器的执行函数体。
- 在新建评估器页面,填写评估器的名称和描述。
- 填写执行函数体。
执行函数体是Code 评估器的执行函数,在评测实验中,扣子罗盘会调用该函数来处理评测对象的输出,以评估其是否符合指定要求。例如检查输出是否包含特定的文本或是否符合特定的格式要求。 - 填写测试数据。
评估器的测试数据用于在创建时试运行评估器,以判断其效果。支持自定义设置和基于评测集构造。- 自定义:创建 Code 评估器时,扣子罗盘会为你构造一个单轮问答的测试数据,你也可以根据自己的执行函数来自定义设计测试数据。关于测试数据字段的详细说明可参考Code 评估器测试数据。
其关键字段说明如下:- evaluate_dataset_fields:评测集字段
- evaluate_target_output_fields:评测对象字段
- ext:补充字段,由开发者自行定义和使用。
配置示例如下:
- 基于评测集:基于已创建的评测集来构造测试数据,更加快捷方便,适用于已有完善的评测集的场景。
- 自定义:创建 Code 评估器时,扣子罗盘会为你构造一个单轮问答的测试数据,你也可以根据自己的执行函数来自定义设计测试数据。关于测试数据字段的详细说明可参考Code 评估器测试数据。
选择**基于评测集**,单击**构造测试数据**。
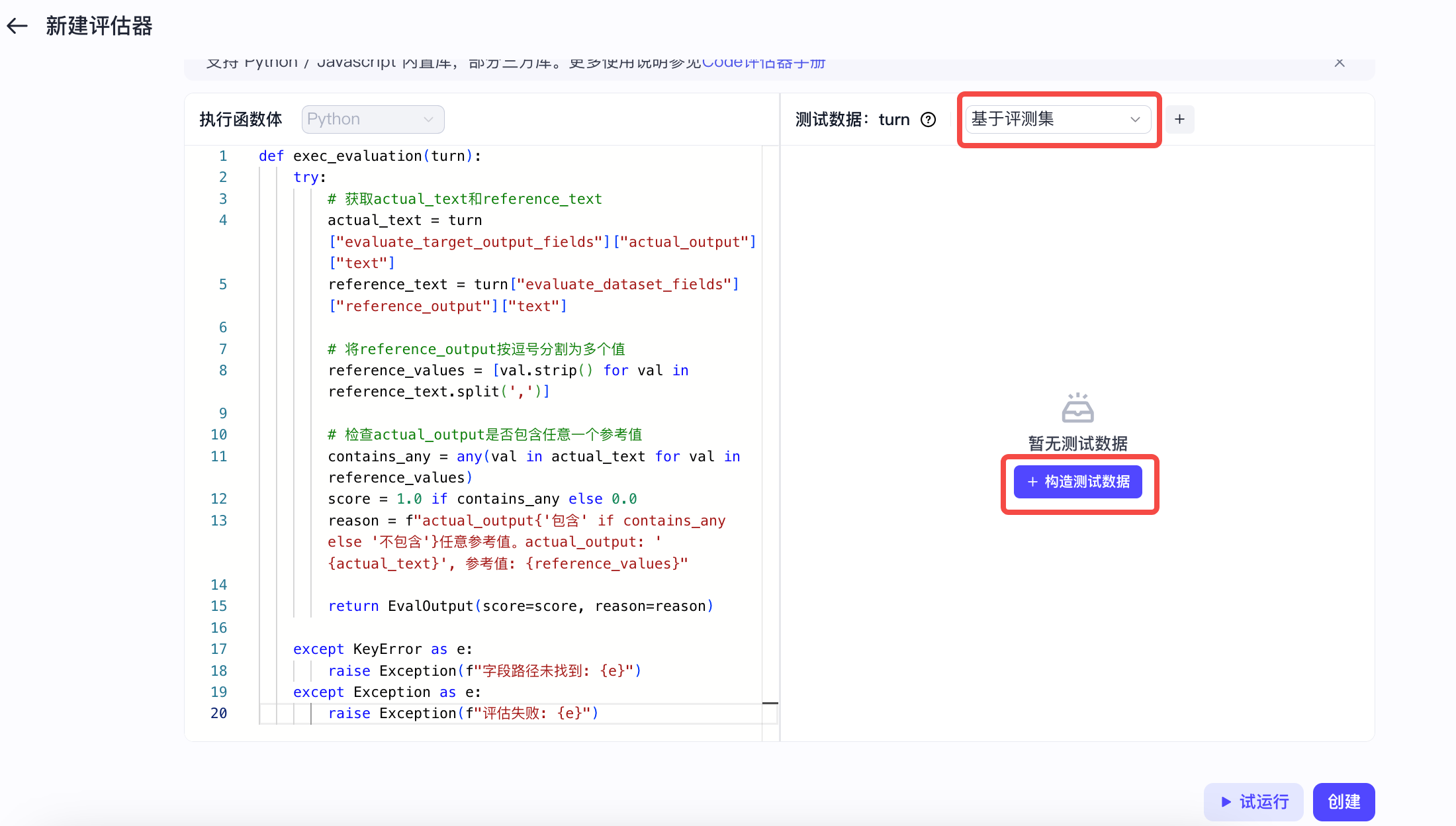
根据页面提示选择评测集、指定版本号,并选择评测集中用于测试评估器的数据。
选择评测对象及版本。
确认测试数据,扣子罗盘会自动生成模拟输出。
示例如下:
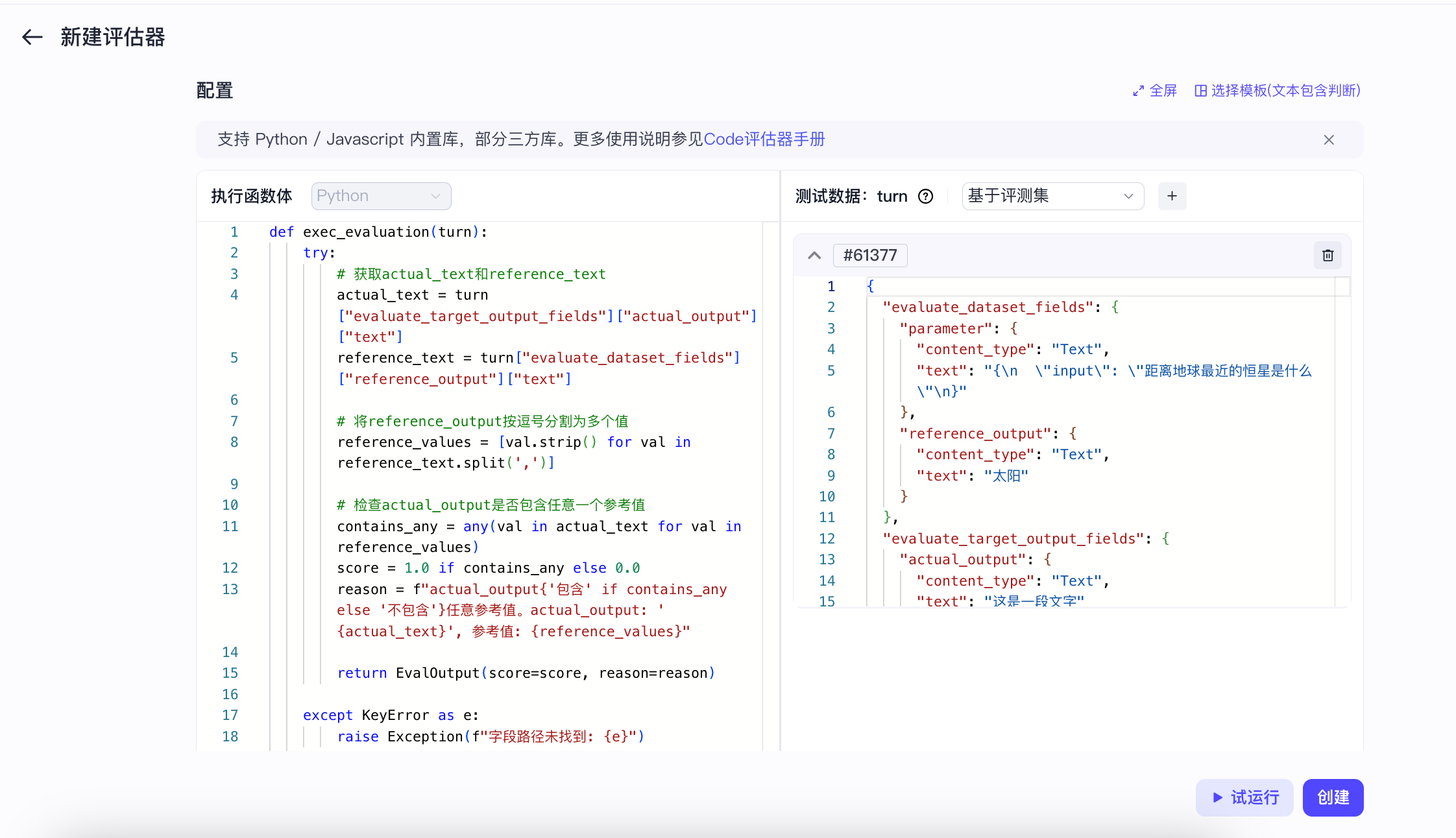
- 在弹出的预览与调试页面,输入一组测试数据,然后单击运行查看评估效果是否符合预期。
以下图中的评估器为例,它对构造的output内容评估完全准确。
- 在调试后,单击创建,并根据页面提示单击检查,提交评估器版本。
扣子罗盘会执行代码语法检查,检查通过后才能提交评估器版本。
管理自建评估器
- 复制、删除、查看评估器:在评估器列表页面,你可以查看、复制、删除已创建的评估器。
- 管理自建评估器版本:你可以在评估器详情页面,修改评估器配置,然后提交新版本。
使用评估器
评估器主要的使用场景是用于在评测实验。结合评测集的输入,对评测对象的输出进行评估打分。在一个评测实验中,可以配置多个评估器或同个自建评估器的不同版本,详情请参考管理实验。
|
场景 |
配置方式 |
|---|---|
|
迭代评估对象 |
在多个实验中,控制评估器不变,配置不同的评测对象( Prompt 的不同版本),查看评测结果。 |
|
迭代评估器 |
在同个实验中,评测对象保持不变,配置同个评估器的不同版本,查看评测结果精确度。 |
相关信息
Code 评估器测试数据
推荐采用如下单行样本结构,便于在离线与在线评测之间统一格式,并与评估器的输入协议对齐:
{
"evaluate_dataset_fields": {
"input": {"content_type": "Text", "text": "问题或输入"},
"reference_output": {"content_type": "Text", "text": "理想答案或参考输出"}
},
"evaluate_target_output_fields": {
"actual_output": {"content_type": "Text", "text": "待评测模型的真实输出"}
},
"ext": {
"dataset_version": "v2025-09-26",
"sample_id": "uuid-xxx"
}
}
字段说明:
|
字段名称 |
字段说明 |
|---|---|
|
evaluate_dataset_fields |
数据集输入数据。 |
|
evaluate_target_output_fields |
评估对象输出数据。 |
|
input |
数据集输入,代表用户问题或任务描述。 |
|
reference_output |
理想输出或标准答案,用于对齐实际输出。 |
|
actual_output |
被评测对象的真实输出,用于打分与误差分析。 |
|
ext |
元信息,用于开发者自行定义使用,通常被定义为数据版本、样本 ID、来源渠道等。建议统一键名便于追踪。 |
|
content_type |
与内容匹配的类型标记,多模态样本应按类型选择相应结构,避免混用。常用枚举值包括 Text、Image、Audio、MultiPart 等。 |
content_type 的完整枚举值及各个类型内容的详细配置可参考以下 IDL:
typedef string ContentType(ts.enum="true")
const ContentType ContentType_Text = "Text" // 空间
const ContentType ContentType_Image = "Image"
const ContentType ContentType_Audio = "Audio"
const ContentType ContentType_MultiPart = "MultiPart"
const ContentType ContentType_MultiPartVariable = "multi_part_variable"
struct Content {
1: optional ContentType content_type (go.tag='mapstructure:"content_type"'),
10: optional string text (go.tag='mapstructure:"text"'),
11: optional Image image (go.tag='mapstructure:"image"'),
12: optional list<Content> multi_part (go.tag='mapstructure:"multi_part"'),
13: optional Audio audio (go.tag='mapstructure:"audio"'),
}
struct AudioContent {
1: optional list<Audio> audios,
}
struct Audio {
1: optional string format,
2: optional string url,
}
struct Image {
1: optional string name,
2: optional string url,
3: optional string uri,
4: optional string thumb_url,
}